A tokenizer represents an image as a set of discrete tokens. In practice, the goal is to achieve high-quality reconstruction while using a limited number of tokens. These tokens are typically later used in a generative model, such as an autoregressive model, for image generation.
The standard approach maps an image into a fixed grid of tokens (which we refer to as 2D grid tokens) (e.g., VQ-VAE, VQ-GAN). However, this method implicitly assumes that information is distributed uniformly across the spatial grid of the image. In reality, this assumption does not hold: different regions of an image may require very different representational capacities (e.g., a large sky region versus a dense crowd).
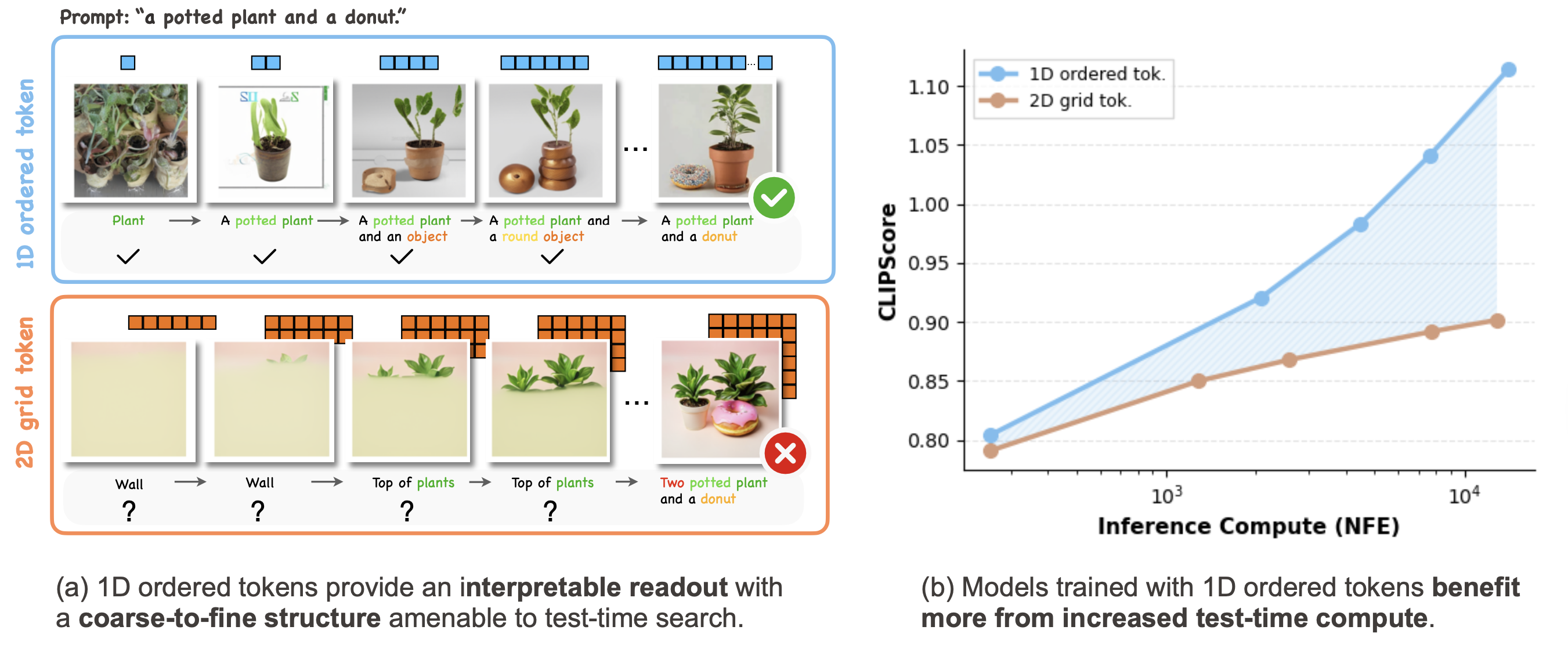
To address this limitation, 1D tokenizers (e.g., TiTok) represent an image as a 1D sequence of tokens, removing the rigid spatial grid constraint. Subsequent works such as FlexTok and Semanticist further introduce structured token sequences, where images are represented with flexible-length tokens and a coarse-to-fine ordering (e.g., via nested dropout). We refer to this family of representations as 1D ordered tokens, which is the primary focus of this work.
In this paper, we argue that the ordering of tokens plays an important role in the test-time scaling (TTS) performance of autoregressive models trained on top of such token structures. In the remainder of this section, we illustrate how the token structure provides a useful representation for search.

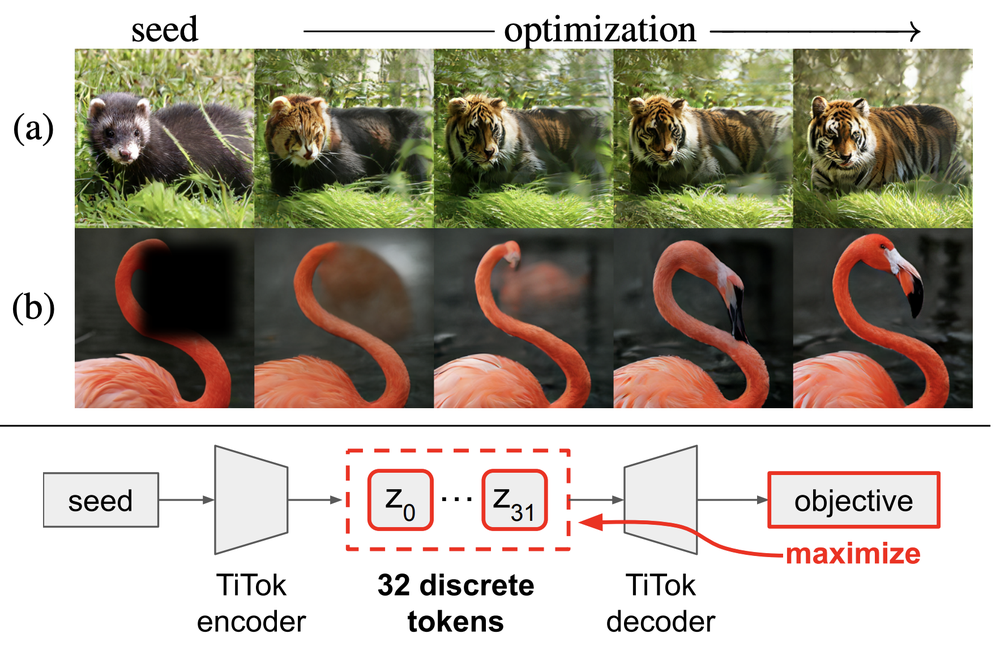
In the figure above, we show an example of the tokenization and detokenization process using FlexTok, a representative 1D ordered tokenizer. An image is first tokenized into a sequence of tokens and can later be detokenized into images using different token lengths. As the number of tokens increases, the reconstructed images reveal a coarse-to-fine progression of information, where early tokens capture global structure while later tokens refine finer details.
In addition, by changing the random seed of the flow-based detokenizer, different decoded images can be generated from the same token sequence. Although these images vary in appearance, they share consistent semantic characteristics. Observing these similarities reveals that individual tokens capture underlying concepts or distributions within the image representation.
Below, we visualize images detokenized from the first token in FlexTok to understand the visual vocabulary it captures. As shown, each token tends to correspond to certain semantic concepts (illustrated by the nine detokenized images generated with different seeds). Browsing across tokens reveals that the first-token space covers a broad range of semantic categories. For example, if one wishes to find a token representing a concept such as "shoes," it is often possible to identify one by searching through images decoded from individual tokens.
However, generating more structured scenes, such as "a group of sheep standing in the grass," is more difficult and may require multiple tokens to capture the necessary semantic and compositional information. This observation suggests that the token space can be viewed as a tree-structured search space, where tokens progressively refine the generated image.
The broad visual vocabulary captured by the first token, together with the coarse-to-fine nature of the token sequence, naturally raises the question: can the token space be viewed as a tree structure, where tokens progressively refine an image? If so, it becomes possible to perform tree search over tokens to find images that best satisfy a given criterion. The figure below shows this concept.

To examine this intuition, we perform beam search over FlexTok tokens (beam size = 5). At each step, we randomly sample 1% of the 64K token vocabulary as candidate tokens for each beam. Each candidate token sequence is detokenized into an image and scored against the text prompt, and the resulting scores are used to retain the top beams for the next search step. We use ImageReward as the scoring function, as it evaluates both image-text alignment and aesthetic quality of the generated images.
We test this approach on prompts from GenEval and COCO. Surprisingly, even without training an autoregressive model, the search procedure can produce reasonable images, including complex prompts involving multiple objects, colors, and spatial relationships. Three examples are shown below.


We observe that early tokens often correspond to concepts that are semantically close but not exactly matching the prompt. As more tokens are added, the generated images become more aligned with the prompt and additional visual details gradually emerge. Quantitatively, this method achieves 79% accuracy on the GenEval single-object category. We refer readers to the section Impact of AR Prior Strengths for more visualizations and quantitative results.
The previous results suggest that 1D ordered tokens exhibit a strong coarse-to-fine structure, making them naturally amenable to search. This property is also closely related to the test-time scaling behavior of AR models. In this section, we describe how test-time search can be combined with AR models and identify the key factors involved.
AR models are typically trained to model token-sequence probabilities, either conditioned on text or unconditionally. This can be viewed as a prior distribution over token space, which helps constrain search and encourages exploration in more reliable regions.
To systematically study test-time scaling for a given token structure, we focus on three components: search algorithms, verifiers, and AR-prior strength. The figure below illustrates this framework (click each block to see details). We refer to this evaluation framework as Search-over-Tokens (SoTo) and open-source the codebase as an extensible platform for studying test-time scaling in autoregressive models.
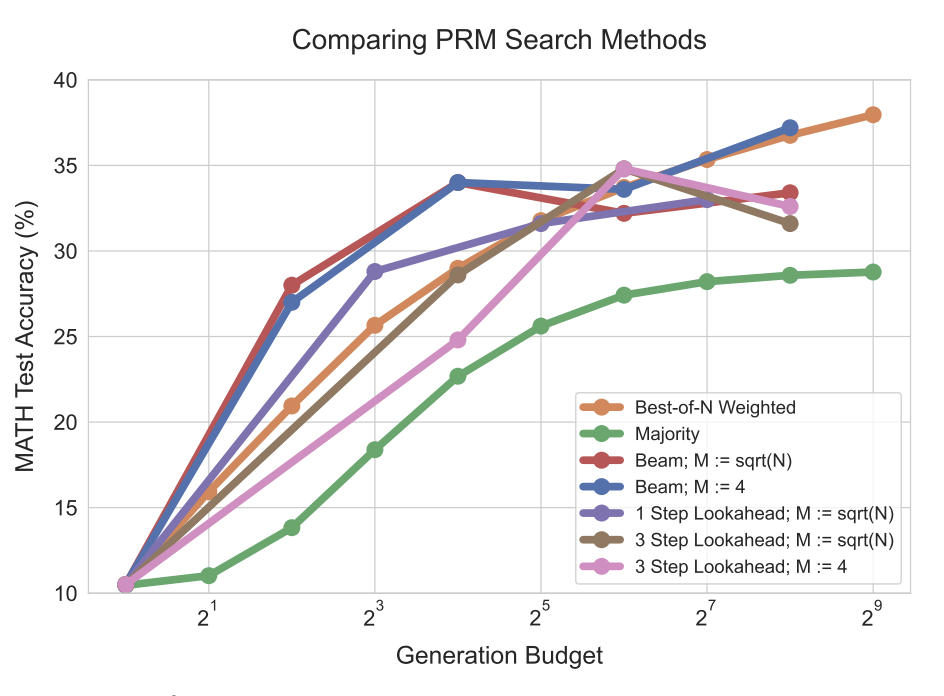
We study three popular search algorithms combined with AR image generation models.
- Best-of-N samples full completions and scores them at the end.
- Beam search keeps a small set of promising partial sequences and prunes incrementally.
- Lookahead search extends partial sequences farther before scoring, trading more compute for stronger guidance.
We consider a broad range of verifiers that can be grouped into three categories based on their utility:
- Image-text alignment: Measures image-prompt correspondence using CLIP, reward models (ImageReward, CycleReward, PickScore, HPSv2), AR self-likelihood, and rule-based verification with GroundedSAM.
- Image-image alignment: measures similarity to a reference image (e.g., DreamSim).
- Image quality verifiers: assess fidelity or aesthetics independent of text (e.g., aesthetic predictors).
We also explore ensembles that combine multiple verifiers.
We consider three priors:
- Text-conditioned prior: token probabilities are conditioned on the input text prompt;
- Unconditional prior: token probabilities are computed without conditioning on text;
- Uniform prior: removes learned preferences entirely.
This lets the framework separate what comes from the model's learned distribution versus what comes from search and verification at inference time.
Key idea: Coarse-to-fine ordered tokens are more amenable to search.
This is because early tokens capture high-level structure while later tokens refine details. As a result, intermediate decoding steps become informative about the final image, allowing search algorithms to evaluate and prune candidates more effectively.
This enables:
Our experiments show that:
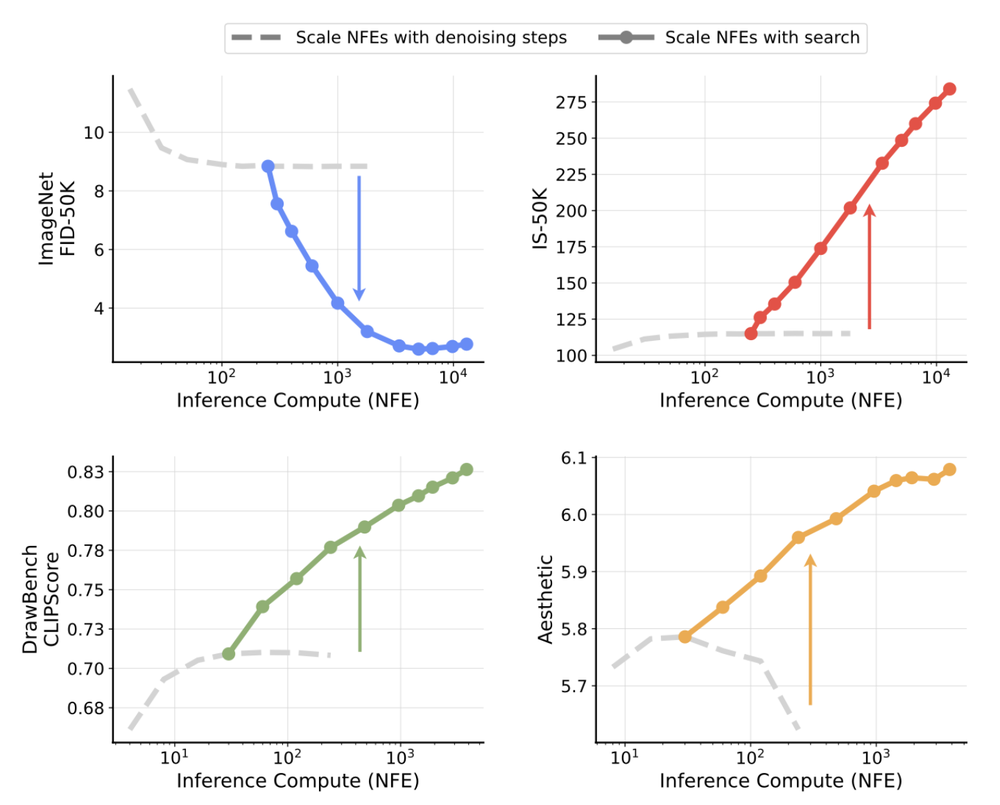
Takeaway: Future research in tokenization and generative modeling should go beyond evaluating generation quality at a fixed inference budget and instead consider how models scale with additional test-time compute.
Our work primarily uses search as a diagnostic tool, rather than proposing new search algorithms. Future work could design search strategies that better exploit ordered token structures. Developing stronger verifiers, especially those aligned with human preferences and capable of providing localized feedback, could further improve search performance.
Our experiments focus on a 1D ordered tokenizer with a flow-based detokenizer, which requires multiple denoising steps. Future work could explore:
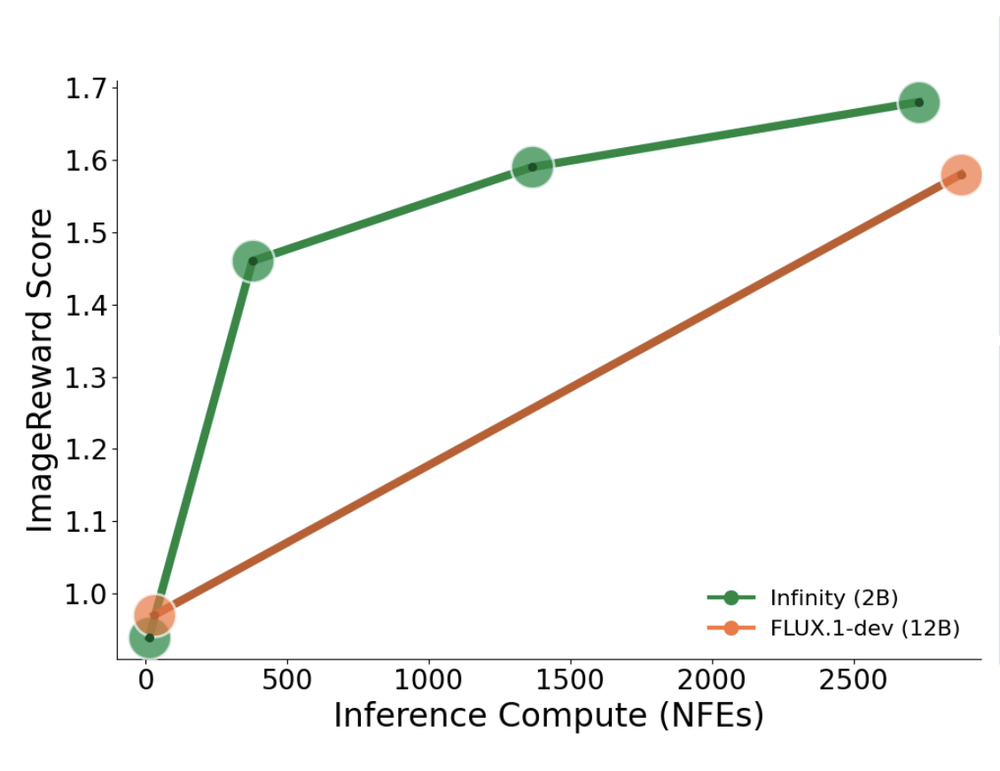
Our experiments focus on FlexTok, currently the only ordered-token autoregressive model supporting text-to-image generation. Evaluating additional ordered-token models will help verify the generality of our findings. It would also be interesting to investigate whether similar benefits extend beyond images to text, video, or other modalities.
Finally, it would be interesting to compare ordered-token autoregressive models with alternative frameworks such as MaskGIT or diffusion models, where tokens correspond to fixed spatial locations and generation proceeds through iterative refinement rather than strict autoregressive ordering.
A small, non-exhaustive selection of work related to this project: 1D ordered tokenization for image and video, test-time scaling across LLMs, diffusion, and autoregressive models.
@article{soto,
title={(1D) Ordered Tokens Enable Efficient Test-Time Search},
author={Zhitong Gao and Parham Rezaei and Ali Cy and Mingqiao Ye and Nata\v{s}a Jovanovi\'{c} and
Jesse Allardice and Afshin Dehghan and Amir Zamir and Roman Bachmann and
O\u{g}uzhan Fatih Kar},
journal={arXiv 2026},
year={2026}
}We thank Ali Garjani and Jiachen Lu for constructive discussions and assistance in preparing the manuscript. We are also grateful to Muhammad Uzair Khattak, Mingfei Gao, and Anders Boesen Lindbo Larsen for their valuable feedback on earlier versions of the manuscript. We further thank Yizhou Xu and Zhekai Jiang for helpful discussions on the theoretical aspects of this work, as well as Vikhyat Agrawal and Yuanzhong Chen for feedback on the codebase and its extensions.